
英特尔携中国电信积极探索基于至强CPU平台
背景与挑战:中国电信网络大模型推理需平衡性能与成本
行业大模型凭借其出色的学习能力、强大的表示和泛化能力,以及针对行业特点进行的专业化增强,正在越来越多的领域得以成功应用,充分展露其巨大的潜力和商业价值。在信息通信领域,随着中国电信等电信运营商逐步向智能数字服务提供商转型,新一代云网融合环境对网络运营智能化的需求日益增长,正推动运营商们借助行业大模型来化解在运维、运营、安全、数据分析以及管理等方面面临的新挑战。
依托丰富的业务场景需求、海量的网络数据知识优势,以及雄厚的云、网及AI技术积累,中国电信在业界率先发布网络大模型,并借助电信行业专属多样化语料库、高效的对话管理机制、高质量语料自动生成与多路检索增强生成能力等一系列面向云网环境运营需求的关键技术与创新能力,以及多种形式的模型即服务(Model as a Service,MaaS)能力,为运营商网络的“规、建、 维、优、营”全生命周期赋能。
在实际的应用过程中,大模型的推理速度快慢与精度高低都会影响使用体验,特别是在网络排障这类争分夺秒的应用场景中,推理效能不足会带来巨大的生产压力。与此同时,持续的技术创新和系统演进,也会使模型参数量和计算复杂度增加,这些都给AI推理算力平台的性能提出了更为严苛的要求。
因此,在构建大模型推理算力方案时,中国电信需要充分考量全国各省的网络运维和管理人员在使用网络大模型执行云网运营、参数调配、故障处置等应用时所承受的巨大并发推理压力和性能要求。就性能而言,业界一般认为生成时延低于100毫秒是使用者能够接受的性能阈值(在聊天机器人中实现100毫秒以内的单词生成,这基本超过了人的阅读速度,对话就显得流畅且自然),方案需要满足该性能需求。
GPU作为目前业界主要智能算力类型,虽然能为大模型推理提供充足算力,但使用其构建推理方案会面临建设成本高、获取渠道有限制等多因素的挑战。中国电信对于“降本增效”的诉求使其需要寻找兼顾性能与经济性的算力方案。
解决方案:基于第五代至强® 的CPU算力方案为中国电信网络大模型提供高效能推理
CPU在传统上被视为更适于AI负载中的通用计算,例如大模型应用的前期数据准备、知识库的存储和处理等工作。随着更多AI加速技术嵌入CPU,以及围绕CPU平台的AI生态逐步完善,CPU平台所具备的多项优势使其能在满足大模 型推理性能的同时,又可兼具成本、绿色节能等方面的优势。
基于这些优势,中国电信联合英特尔,将英特尔® 至强® 可扩展处理器引入中国电信网络大模型的基础算力平台,积极探索基于CPU平台的大模型推理方案,化解大模型推理能力下沉到省公司的挑战,并为满足各行各业对大模型推理算迫切需求探索新路。
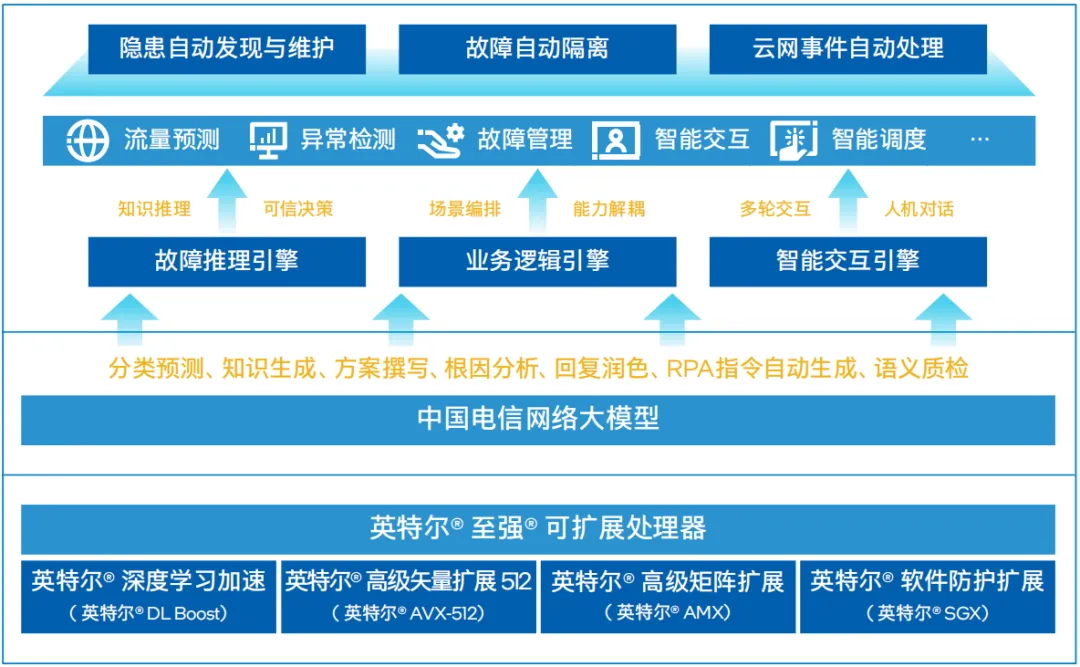
如图所示,方案使用第五代英特尔® 至强® 可扩展处理器作为 算力核心。通过其内置的英特尔® AMX、英特尔® AVX-512等AI引擎提供的加速能力,中国电信网络大模型能通过分类预测、 知识生成、方案撰写、根因分析等能力向上打造智行云网大脑。大脑以故障推理、业务逻辑以及智能交互等多个引擎为驱动力,在流量预测、异常检测、故障管理等云网场景中实现隐患自动发现与维护、故障自动隔离以及云网事件自动处置等网络运营智能化能力。各级运维人员接入后,可以通过知识问答、信息筛选和总结等交互方式,直接使用大模型的推理结果。

第五代英特尔® 至强® 可扩展处理器实现高效的大模型推理的技术关键要素
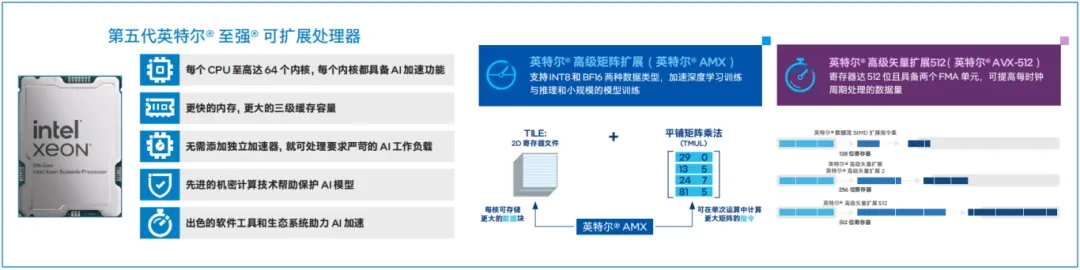
面对高强度、高并发的大模型推理需求,第五代英特尔® 至强® 可扩展处理器不仅具有更多的内核数量、更强的单核性能和更大的三级缓存(LLC)容量,还可凭借增强的内存子系统,以及全面的AI加速环境来为大模型提供强劲的推理算力支持。
• 更大的三级缓存,消除内存瓶颈
在传输故障处置方案推荐等应用场景中,有大量网络相关的数据需要被快速读取和处理,网络大模型面临着长输入输出(例如超过几K的输入输出)、大Batch Size(例如大于128)的需求。同时,针对不同的网络情况,可能也需要多种模型同时在线执行,此时的内存容量、带宽等就可能成为瓶颈。 第五代英特尔® 至强® 可扩展处理器提供了更大的三级缓存,使大多数模型参数能够保存在其中,使推理速度获得大幅提升;同时,每路处理器可支持8个DDR5-4800内存通道,能够释放和加速高内存需求推理计算时的工作潜能。
• 内置AI加速引擎,大幅提升推理效能
第五代英特尔® 至强® 可扩展处理器内置多个可加速大模型推理的AI引擎。英特尔® AMX在运行时直接采用分块矩阵乘法的方式,其内部所定义的Tile矩阵乘法(Tile Matrix Multiply Unit,TMUL)加速模块能够直接对矩阵寄存器中的数据实施矩阵运算操作。因此,低精度的数据格式能极大提升运算效率,在保证精度影响最小的前提下加速推理过程。英特尔® AMX支持INT8和BF16低精度数据类型,在矩阵运算中能有效提高计算速度并减少存储空间占用,更充分地利用计算资源,显著提高每个时钟周期的指令数,配合全方位的软件生态和优化方案,可大幅提升网络大模型在各应用场景中的推理效能。
英特尔AI软件工具助力大模型推理性能进一步提升
在软件层面,方案还引入一系列英特尔AI软件工具来提升推理性能、降低部署成本以及便捷地迁移模型。其中,xFT作为英特尔开源的一款分布式推理优化框架,能够基于至强® 平台的指令集提供一系列卓有成效的性能优化解决方案,包括张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism)等,并支持 BF16、INT8、INT4等多种数据类型以及多种主流大模型,同时也支持多CPU节点之间的分布式部署方案,使超大模型在CPU平台上的部署成为可能。
如图所示,英特尔提供多种AI软件工具,能够借助插件或开源工具链简单快捷地完成模型迁移,并实现对主流AI开发框架的全面兼容。这使得网络大模型应用在开发时无需额外修改代码即可实现软件从GPU到CPU的迁移,实现“一次编写, 随处部署”。此外,英特尔还提供了PyTorch、TensorFlow等框架的库扩展,有助于相关应用方便地获得最新的软件加速能力。这些优势让中国电信网络大模型能在CPU平台上轻松地进行开发、部署,并实现高效的AI推理。
贴近一线的边缘化部署和绿色节能加成
在产品形态和资源需求方面,如图四所示,中国电信将网络大模型部署到省公司乃至生产一线,这就需要数据在边缘侧进行即时/近即时处理。为了更好地满足业务需求并提升使用体验,中国电信选用了符合OTII标准的边缘服务器。
边缘部署的环境复杂性通常比数据中心更高,有时甚至需要在极端恶劣的环境中部署。这意味着边缘服务器需要在功耗、体积、耐用性等方面符合特定要求,能在极端高低温、灰尘、腐蚀、震动冲击、电磁干扰等情况下保持稳定运行。得益于在配置规格、物理形态、供电及环境适应性等方面的设计,符合OTII标准的边缘服务器能够让中国电信根据工作负载精细地调整基础设施功能,无需改造大量的边缘机房即可支持边缘侧的大模型推理,实现性能和总拥有成本(Total Cost of Ownership,TCO)等方面的均衡。
此外,由于CPU的运行功耗低于GPU,可以显著降低网络大模型运营所需的能耗。以第五代英特尔® 至强® 可扩展处理器为例,得益于多种创新技术和功能的加入,以及工艺制程与封装技术的不断升级,功耗获得持续优化,相比前一代产品的开箱即用能耗比提升高达34%2 ,并可通过启用平台BIOS中经优化的电源模式,为特定工作负载进一步提高能效和节省成本,从而帮助中国电信更好地实现节能减排,贴近绿色算力的发展目标。
成果验证与应用成效:全方位赋能网络运营, 提升客户体验
为验证大模型推理CPU上的部署可行性,中国电信研究院联合英特尔在ETSI ENI行业规范工作组中,开展了至强® CPU支持大模型推理的验证工作,推动业界一起关注为解决大模型算力需求的创新型解决方案。该PoC项目情况及验证结果由ETSI公开发布,详见ETSI网站。
同时,2024年6月,中国电信携手英特尔,通过在标准服务器/OTII服务器上配置第五代英特尔® 至强® 可扩展处理器并使用xFT框架,分别部署中国电信网络大模型(13B参数)和开源Qwen大模型(参数量14B),由中国权威测试机构实验室进行了全方位的测试。
中国电信网络大模型的验证测试如表一所示,涵盖了规章制度、 维护要求、维护问题等多个场景。
测试总结如图五和表二所示,中国电信网络大模型在吞吐量、首字符时延和生成时延方面都与规模相当的开源大模型性能表现一致,在CPU平台上的生成时延均小于100毫秒5 ,符合业务响应时间要求,可以满足电信网络运营维护等多场景推理应用需求。同时,中国电信网络大模型的生成内容也符合预期,性能精度达到了设计需要。测试结果也表明,基于现有x86架构的算力平台,可以满足运营商推理应用需求,有利于降低运营商在大模型算力领域的成本及资源需求。
目前,中国电信网络大模型已深度嵌入到中国电信集团及省OA (移动端)、中国电信大模型平台(Web端)等现网系统,完成全网部署。其提供的MaaS的服务新模式,不仅能应用于中国电信O域和B域的态势感知、故障处置、应急保障、工单质量稽核、无线网优、流量预测以及知识检索等场景,也能从点到面,在网络运营全生命周期中实现全方位赋能,提升客户体验。
在实际应用中,中国电信网络大模型通过大小模型协同,为中国电信全网运维/运营人员提供助力,辅助一线人员高效完成综维、装维任务,提高效率,并已在中国电信全国多个省份试点中取得出色成果。
• 省份一:方案实现了降低链路拥堵概率,割接时长同比缩短30%至40% ,大幅减少割接风险;
• 省份二:方案在2250余条链路中被用于判定链路中断后网络是否会发生拥塞,降低割接人工时长约60% ;
• 省份三:方案降低割接风险约80% 。 同时,大模型也面向云网工程师,打造了涵盖知识问答、辅助助手和智能体三个维度的3类12个AI助手,实现问答答准率85%、方案生成可用率90%、故障处置效率提升30%、高危指令稽核效率提升50%的总体目标。
实践证明,基于CPU平台进行大模型推理,显著降低了大模型推理算力建设和运营成本,也再次打破传统的GPU推理思路。根据中国电信的测算,与主流GPU相比,CPU平台方案可节省算力资源池建设成本超40%。此外,CPU作为通用计算资源,更易获取且使用成本和维护成本都比较低,结合CPU平台在绿色节能方面的优势,为中国电信网络大模型的规模部署提供了创新、经济和可扩展算力选择,为智算资源的建设提供了全新思路,
未来展望
在结合新一代云网环境,探索电信领域行业大模型的构建与实践中,中国电信正借助网络大模型的优势及基于英特尔® 架构的CPU平台所提供的强劲大模型推理能力,推动网络运营智能化,提升运营商网络的自智水平。基于CPU的网络大模型推理方案的提出与验证已证明,CPU方案能兼顾应用性能与部署经济性,显著降低建设和使用成本,有助于大模型在各行各业的落地与推广,助力数字经济智能化发展。该创新方案还于2024年9月入围了2024年第二届“华彩杯”算力大赛决赛。
面向未来,中国电信将持续加强科技创新投入,与英特尔等合作伙伴开展更大范围、更深层次的全面合作,共同推动大模型推理在CPU上更多的部署和优化,为网络大模型在云网融合更多场景应用打造新典范,并赋能其在更多行业落地与规模推广,为经济社会的数字化转型贡献力量。